ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte II
Publicado por Juan Pablo el 2.Abr.2006 | Comentarios (18)
Hola, bienvenido a la segunda parte y final de la historia sobre la Iñtërnâçiônàlizæçiøn de nuestro intercambio de información sin problemas de codificación. La entrega pasada tuvo mucho exito, espero cumplir vuestras expectativas para el final de la historia.
Convención y ayuda
Para es artículo definiremos algunas convenciones de notación:
- 0x21: quiere decir, número hexadecimal 21
- b110: número binario 110
Si quieres realizar tus propios cálculos entre bases numéricas puedes ayudarte de Google:
- 0x21 en decimal
- bx110 en decimal
Recapitulando
Algunas ideas de la entrega pasada para refrescar la memoria.
- Definimos un par de conceptos respecto a los caracteres
- Vimos el primer código de caracteres de la historia: US-ASCII
- Mostramos los problemas que trajo consigo tantos códigos de caracteres
- Relatamos el nacimiento de un estándar: Unicode
- Y terminamos deliniando los problemas que también tenía el nuevo estándar Unicode.
Ahora definiremos oficialmente el sistema de codificación Unicode llamado UTF-8, además ilustraremos los problemas típicos y sus soluciones. Terminaremos migrando un weblog corriendo en Wordpress con ISO-8859-1 a UTF-8, como vez hay mucho paño que cortar asi que... ponte cómodo.
ISO-8859-1 o Latin 1
Para los que leyeron el artículo anterior se dieron cuenta que nunca mencioné el juego de caracteres ISO-8859-1, debo ser honesto y reconocer que se me quedó en el tintero, pero aquí me reivindico.
¿Se acuerdan de la desaparecida empresa Digital?, la que luego fue comprada por Compaq. Bueno, Digital fue una empresa pionera en la industria de la computación, entre sus muchos aportes desarrollaron un terminal llamado VT220 que traía consigo un juego de caracteres que ellos llamaron Set de caracteres Multinacional que fue desarrollado por ECMA. En 1992 IANA presentó el mapa de caracteres ISO_8859-1:1987, más conocido como el ISO-8859-1 el mismo que fue la base para los VT220 ahora era la base para la naciente Internet. El ISO-8859-1 es un set de caracteres de 8 bit de longitud, define la codificación del alfabeto latino incluyendo los diacríticos (á,é,ñ,ç) y letras especiales (ß, Ø) necesarios para las lenguas:
- afrikaans,
- alemán,
- aragonés,
- catalán,
- danés,
- escocés,
- español,
- feroés,
- finés,
- francés,
- gaélico,
- gallego,
- inglés,
- islandés,
- italiano,
- neerlandés,
- noruego,
- portugués,
- sueco y vasco.
Por esta razón el ISO-8859-1 también es conocido como el Latin 1. La inmensa mayoría de los sitios web de occidente utilizan éste juego de caracteres pero ¿qué ocurre con los sitios de oriente?, donde el ISO-8859-1 no sirve. Para sintetizar tenemos el mismo escenario de problemas ocurrido en la entrega pasada de este artículo y la carta de mi primo Aristóteles: ¡aunque exista ISO-8859-1 todavía no tenemos un estándar!.
Finalmente: Unicode Transformation Format-8
Como habíamos descrito en la entrada anterior Unicode es el estándar que albergaba todas las lenguas de la tierra, sin excepciones, pero ¿cómo representamos Unicode para no provocar problemas en nuestros sistemas?; un gran dilema; hasta que llegó el señor Ken Thompson (el mismísimo patriarca de Unix) acolitado por Rob Pike. Estos señores inventaron la forma de codificar Unicode mientras cenaban en un restaurant de Austin, Texas ¿Pero de qué se trataba tal genialidad?, aquí vamos:
- El bit más significativo de un carácter de byte-simple es siempre 0
- Los bits más significativos del primer byte de una secuencia multi-byte determinan la longitud de la secuencia. Estos bits más significativos b110 para secuencias de dos bytes; b1110 para secuencias de tres bytes, etc.
- Los bytes restantes en una secuencia multi-byte tienen b10 como sus 2 bits más significativos.
Más claro que eso imposible ¿verdad?, era una broma (risas por favor). De los puntos anteriores se genera la siguiente tabla de tranformación:
Rango Unicode | UTF-8 secuencia de octetos (hexadecimal) | (binario) --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 0020 0000-03FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0400 0000-7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Me encantan los ejemplos, vamos con algunos:
- Tómese el caracter H (Letra "H" latina mayúscula). Su punto de código (Unicode) es el U+0048, 0x48 es menor que 0x7F por lo tanto tenemos que leer de la primera fila. El binario del hexadecimal 0x48 es b1001000, por lo tanto el punto de código U+0048 se guardará en disco u/o memoria como b1000001. ¡Hey!, espera un momento... pero este número binario yo lo conozco, ¿no es el mismo número binario usado para representar la misma "H" según la tabla US-ASCII? (véase artículo anterior)— mhhh, veo que eres una persona observadora— tienes razón, es el mísmo US-ASCII original y he aquí algo importantísimo. Toda la tabla US-ASCII, es decir, aquellos 127 caracteres son exactamente los mismo en UTF-8, tienen la misma representación escalar; con eso preservamos la compatibilidad hacia atrás.
- Caracter a (Letra latina "a" minúscula)
-
Tómese el caracter Ñ (letra "Ñ" latina mayúscula).
- Punto de código : U+00D1
- 0xD1 > 0x7F, por lo tanto NO corresponde al primer rango
- 0xD1 < 0x7FF, rango correspondiente a la segunda fila.
- 0xD1 = b11010001
- Según la tabla se utilizarán dos bytes para representar la "Ñ", es así como b11010001 se transformará en: b11000011 b10010001, su equivalente hexadecimal es 0xc3 y 0x91 respectivamente.

- Veamos un cuarto y último ejemplo. Letra mongolania Ali Gali Baluda
Eso es UTF-8 y cómo trabaja, una cosa más: el número "8" equivale a la longitud de cada octeto, 8 bits. Debo mencionar —o mejor dicho clarificar—que UTF-8 es una forma más de representar Unicode, otras alternativas son UTF-16, UTF-7, SCSU.
Basta de teoría: Problemas del mundo real
Muy bien, hasta aquí todo ha sido un mar de aburrida teoría, ataquemos los problemas del mundo real. Imagino que te has dado cuenta que soy un instigador del uso de UTF-8, ¡usa UTF-8! ...¿convencido?—excelente. ¿Por donde comenzar?, aquí vamos:
Texto codificado hay en todos lados: en un email, en una página web o en un script; supongamos que tienes una página web codificada con ISO-8859-1 al igual que la inmensa mayoría de las páginas web de occidente, para cambiarte a UTF-8 debes:
- Usuario Windows
-
-
La w3c dice que todo documento transmitido por HTTP que sea de tipo texto— texto plano, html, etc —debe tener un parámetro
charsetque especifique la codificación de caracteres del documento, dicha línea es la siguiente:<meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1">Abre el archivo con tu editor favorito —el Bloc de Notas de Windows 2000/XP resulta ser muy útil— y cambia la línea mencionada por:
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">Da exactamente lo mismo si lo escribes con mayúscula (UTF-8) o minúscula (utf-8) (ver especificaciones en IANA)
- Ahora haz un "guardar como" teniendo la precaución de que la codificación sea UTF-8, si eres usuario de Vim los pasos son los siguientes:
- Con el archivo abierto y en modo normal tipea :set fileencoding=utf8
- Guarta y listo
- Te recomiendo dejar en tu _vimrc la línea set encoding=utf8, de esta forma todos los archivos que edites de ahora en adelante serán codificados en UTF-8.
Si no usas Vim, te recomiendo ver cómo se configura la codificación en otros editores.
-
- Usuario Unix/Linux
-
En un entorno Unix/Linux tenemos otra alternativa para cambiar la codificación de nuestra página web, y se llama iconv, el comando sería:
iconv -f iso-8859-1 -t utf-8 entrada-iso.html -o salida-utf.html
-f: from, -t: to. o: out. Si quieres conocer la lista completa de los sistemas de codificación soportados por iconv tipea: iconv -l
- Usando tu editor favorito cambia el
charset(mira el punto 1 del ejemplo para Windows).
El test del Ñandú
Veamos más problemas típicos relacionados con el sistema de codificación de nuestras páginas webs. Es muy común que ocurran conflictos de codificación entre nuestro servidor web y las páginas cuando decidimos cambiarnos a UTF-8. Cuando un servidor web es instalado, el administrador le dice qué sistemas de codificación son aceptados y cuál es el sistema por defecto. En un servidor Apache la línea de configuración es la siguiente ( la cual está dentro del archivo httpd.conf):
AddDefaultCharset
Ésta directiva acepta tres (3) valores: On|Off|charset
Supongamos los siguientes escenarios, pero antes: El Administrador es el señor que configura nuestro servidor web y nos permite alojar nuestra página web, el Desarrollador es quién hace la página web. El Administrador configura la directiva AddDefaultCharset, el Desarrollador configura el charset de la página (su codificación) y ahora veamos que sucede con las diferentes combinaciones que se pueden dar:
-
AddDefaultCharset on Charset = utf-8

Cuando AddDefaultCharset está en on quiere decir que sea cual sea la codificación que usemos en nuestra página web el servidor siempre servirá la página en ISO-8859-1 —que es la codificación por defecto. Me da para pensar que estamos frente a un Administrador retrógrado y un Desarrollador visionario.
-
AddDefaultCharset Off Charset = utf-8

En este caso nuestro Administrador es un tipo liberal, y da todo el poder de decisión a quienes alojamos nuestra página en su servidor para elegir libremente la codificación (ver todas las codificaciones permitidas por IANA). Por ejemplo, en el hosting donde se aloja actualmente juque.cl mi administrador tiene ésta configuración.
-
AddDefaultCharset utf-8 Charset = iso-8859-1
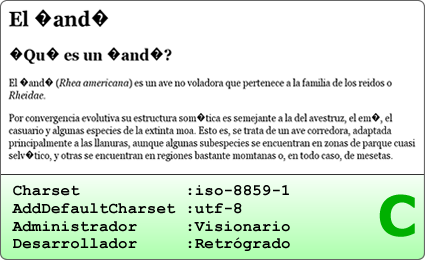
Ahora tenemos un Administrador visionario, quién entiende la importancia de tener una codificación estándar en su servidor, pero el Desarrollador aún tiene la mente en los años 90 y continúa desarrollando para ISO-8859-1.
-
AddDefaultCharset utf-8 Charset = utf-8

Finalmente tenemos un dúo vanguardista, visionario y con un pensamiento estándar además de ser asiduos visitantes de los mejores weblogs de Internet.
El test del Ñandú está disponible para descarga (2 archivos html: ISO y UTF) si quieres probar en tu propio servidor.
¿No tienes acceso al httpd.conf?
Bajaste el test del Ñandú y te diste cuenta que tu caso es el A—el peor de todos— además tienes alojado tu sitio web en un servidor compartido donde no tienes acceso al httpd.conf ¿qué haces?.
En la raíz de tu sitio web, crea un archivo bautizándolo como .htaccess (nótese el punto al inicio). Éste archivo es especial, su nombre técnico es "archivo de configuración distribuido", por decirlo de algún modo es un httpd.conf local, especialmente configurado para un directorio "x", a pedido, moldeado para. Siguiendo el caso D dentro del .htaccess ponemos:
AddDefaultCharset utf-8
Guarda y ¡voila!. Si no lo haz hecho aún, cambia la codificación y el charset de todas tus páginas webs y todo tu sitio web gozará ahora de una dulce atmósfera UTF-8.
Migración por lotes usando jutf8.sh
Unas líneas más arriba migramos una página web de ISO-8859-1 a UTF-8 paso a paso, en un ambiente Windows y en uno Unix/Linux. Ahora haremos lo mismo pero por lotes. Para automatizar la migración de una gran cantidad de páginas he creado un script en Bash que cambia el sistema de codificación existente (configurable) a UTF-8 —usando iconv— además cambia el charset de cada una de las páginas codificadas—usando ex. Los pasos para usar el script son:
- Bajar el script subirlo a tu servidor
- Por defecto el script buscará todas las páginas con extensión .html, edita el script para otra extensión. También puedes editar la codificación original (por defecto es ISO-8859-1)
- Hacerlo ejecutable : chmod 755 jutf8.sh
- Correrlo: ./jutf8.sh
- Para tu tranquilidad el script hará un copia de cada página y le agregará una extension (.nuevo)
- Descargar jutf8.sh
Migrando un Weblog corriendo en Wordpress de ISO-8859-1 a UTF-8
El CMS para weblog's más popular es Wordpress, así que lo usaré de ejemplo para migrarlo de ISO-8859-1 a UTF-8. Para el ejemplo debes tener necesariamente acceso SSH a tu servidor.
-
En panel de administración vamos a : Options → Readings, en Encoding for pages and feeds cambiamos la codificación a: UTF-8
Si en este momento miramos nuestro weblog luce de la siguiente forma:
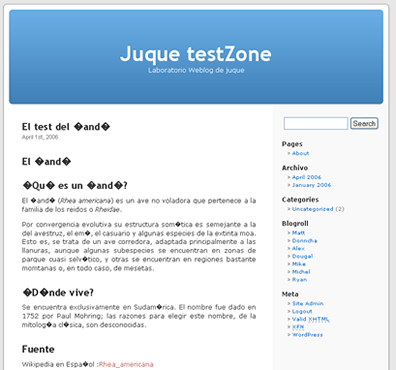
No entres en pánico, ahora lo arreglamos.
-
Te conectas a tu servidor, una vez en la línea de comandos tipeas:
mysqldump --add-drop-table -u tu-usuario -ptu-contraseña -h tu-hosting tu-bd > wp.sql
Explicación de cada parámetro:
- mysqldump: Llama a la aplicación MySQL que hace copias de seguridad de nuestra base de datos.
- --add-drop-table: Agrega la sentencia DROP TABLE (borrar tabla) antes de cada sentencia CREATE TABLE. Aseguramos la creación de la tabla si ésta ya existe.
- -u: nombre del usuario MySQL.
- -p: La contraseña de acceso. Nótese que la p está pegada a la contraseña.
- -h: El nombre del hosting, si es localhost se puede obviar.
- El último parámetro mysqldump es el nombre de la base de datos.
- > indica que se redireccionará el resultado del volcado un archivo llamado wp.sql
-
Ahora cambiaremos la codificación del archivo wp.sql usando iconv, igual como lo hicimos antes.
iconv -f iso-8859-1 -t utf-8 wp.sql -o wp-utf8.sql
-
Sólo nos queda un paso más. Ahora sólo tenemos que volver a subir el archivo a nuestra base de datos, pero ahora usando el archivo recién codificado: wp-utf8.sql. Lo que hacemos posible usando el siguiente comando:
mysql -u tu-usuario -ptu-contraseña -h tu-hosting tu-bd < wp.utf8.sql
- ¡Chas!, weblog con UTF-8.
Problemas en el camino
Mientras hacía las pruebas de rigor en mi laboratorio (que sonó pomposo eso ¿verdad?) tuve algunos problemas. La migración que leiste anteriormente fue hecha en MySQL 3.23, que es la versión que tengo montada en mi casa, la versión de mysqldump es la 8.22. Luego del exito de la migración decidí hacer exactamente lo mismo en Dreamhost (mi empresa de hosting) pero el resultado no fue el mismo, no funcionó la migración.
Mi hosting tiene montada la versión 4.1.14 de MySQL y el mysqldump es la version 10.1. Cuando realicé el paso 2 de la migracion me di cuenta que el archivo valcado ya estaba codificado en UTF-8, de esto no estoy seguro (¿alguién me ayuda?) pero al parecer mysqldump versión 10.1 vuelca siempre en UTF-8 a menos que se le especifique otro juego de caracteres. Entonces quedé plop. Realizando una típida prueba y error comenzé a eliminar algunos comentarios que mysqldump deja en el archivo volcado (wp.sql). Cuento corto, cuando eliminé la línea:
/*!40101 SET NAMES utf8 */;
y después de subir nuevamente el archivo (paso-4) funcionó perfectamente. No hubo necesidad de usar iconv. Mi conocimiento no es muy fuerte en MySQL, si alguién sabe la respuesta por favor deje su comentario. Aunque al parecer es un problema de mi hosting.
Fin de la historia
Espero haber cubierto casi todo el tema Unicode y UTF-8 con estos dos artículos. Los invito a todos a cambiarse a UTF-8 para que nuestro intercambio de datos sea único para todo el mundo, nuestras aplicaciones ajax's no tengan problemas y nuestros archivos XML sean iguales para cualquier tipo de sistema. Acuérdense de mi cuando vean esos trackbacks o pingbacks ininteligibles (con símbolos extraños), uno de esos dos bloggers es un retrógrado.
Electo de enlaces participantes de este artículo
- Converting a Movable Type blog from ISO-8859-1 to UTF-8
- Character encoding
- Unicode Tools
- Convert hexadecimal Unicode escape sequence (\uXXXX) to text
- Character Sets / Character Encoding Issues
- Unicode Transformation Formats: UTF-8 & Co.
- Soporte WP: change from ISO-8859-15 to UTF-8
- Problema con MySQL 4.1 phpMyAdmin y utf-8
- ymipollo.com con UTF-8
Enlace Permanente, Comentarios (18), Publicada en: Estándares
TrackBack
Weblogs que han referenciado la ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte II:
» ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte II de meneame.net
Entrega anterior: http://meneame.net/story.php?id=4670 [continuar leyendo]
» ASCII, Unicode, UTF-8 y la internacionalización de Garbage In, Garbage Out
...i.html">ASCII, Unicode, UTF-8 y la internacionalización, parte 1
ASCII, Unicode, UTF-8 y la internacionalización, parte 2<... [continuar leyendo]
Comentarios
- 1. claudio
- 2.Abr.2006
no quiero ser chupamedias, pero la verdad es que debe ser el post más notable y claro que he leído respecto de los trabalenguas de la codificación.
mis felicitaciones, juque.
- 2. Nelson Rodríguez-Peña
- 2.Abr.2006
¡Me emocionas hasta las lágrimas Juque! ¡Qué articulazo!
- 4. judas
- 3.Abr.2006
/me se saca el sombrero ;)
notable..una de las mejores explicaciones que he leido sobre el tema ..
- 5. judas
- 3.Abr.2006
en el muy bizarro caso que necesitaran hacer dicha conversion en dentro de un mismo archivo PHP que se esta ejecutando , seria algo asi:
final.
je. mientras escribia este codigo, pille un BUG en APC (http://www.php.net/apc/) pero alguien mas ya lo reportó :)
aqui : http://www.onfocus.cl/judas/iso2utf8.py hay otro script en python que serviria para la conversion.
find . -name "*.html" | iso2utf8.pySaludos.
- 6. judas
- 3.Abr.2006
lametablemente el ejemplo en PHP tu blog se lo devoró :D aqui esta el link http://www.onfocus.cl/judas/iso2utf8-inline.phps
- 7. MD
- 3.Abr.2006
Muy buen articulo, se podria desarrollar una 3º parte un poco mas tecnica en relacion a la programacion y UTF-8, que tambien tiene mucha chicha aunque a lo mejor es menos interesante.
- 8. RoQ
- 3.Abr.2006
Excelente articulo, supongo que las dos partes iran en la seccion de recursos.
- 10. Levhita
- 3.Abr.2006
Efectivamente MySQLDump guarda el archivo como utf-8, yo importé la base de datos con el phpMyAdmin de Dreamhost, importandola desde el archivo(es decir no fue copy&paste) e indicando la codificación del archivo(utf-8). Y funciono perfecto.
- 11. judas
- 3.Abr.2006
ahh..y con repecto al asunto de mysql, no esperes que mysql 3 haga nada bien.. ¡¡atento tierra ¡¡ ya va a salir mysql 5.1 ¡¡ :P estas a 7 años de diferencia.. no es precisamente "visionario" usar mysql 3 . je :)
- 12. José Miguel
- 4.Abr.2006
En dos palabras: im-presionante
enhorabuena por este peazo de artículo
- 13. ismael
- 4.Abr.2006
Totalmente notable el artículo. Un "must-read" para los desarrolladores criollos (me incluyo).
- 14. pep
- 11.Abr.2006
Excelente artículo. Y superútil en un momento en que migraba de windows a linux un entorno Apache-PHP-MySql y me estaba volviendo loco. Sólo he encontrado a faltar un pequeño detalle: Porqué no explicas el significado del "Default Character Encoding" del Mozilla Firefox?
- 15. juque
- 11.Abr.2006
@pep: Cuando Apache sirve una página la envía usando la codificación que él tiene configurado (Véase el caso A,B y C). El sistema de codificación seleccionado por Apache será el que el Firefox (o cualquier navegador) tome por defecto.
- 16. Gabriel
- 13.Abr.2006
Buenisimo!!
Realmente estoy en apuros con esto y sin esta información no hubiera tenido como amañármelas (arreglarmelas).
Espero ansioso el capítulo sobre XML (espero no pedir demasiado), y los líos que generan las hojas de estilo (XSL) llamadas desde un objeto del servidor. (Específicamente: usar un XSL desde el XMLDOM de ASP.)
Muchas gracias por tu aporte, beneficioso para esta nube de programadores de habla castellana.
- 17. judas
- 13.Abr.2006
@pep : Ya sea apache o cualquier otro servidor web, este suele enviar un encabezado HTTP ( en ingles "header") que contiene una cierta cantidad de información que el cliente debe o puede interpretar.
en este caso el servidor web enviaría el encabezado "Content-Type" que dentro de sus valores deberia contener el charset en cuestion de el documento, este sera interpretado por cualquier navegador ( inclusive los de texto )
- 18. Leo
- 26.Abr.2006
y no se trató sobre el UTF-8 con BOM... aún me ronda la cabeza qué es exactamente